未来,一个人能运营一家独角兽公司吗?
想象一下,你是 CEO,领导着数百个不间断运行的 AI 智能体,去解决人类最重大的问题。
10000x Engineer pic.twitter.com/zLwGV3q7a9
— shafu (@shafu0x) February 6, 2026
Open Multi-Agent Runtime
虽然万倍工程师的生产力远超我们最大胆的想象,但这样的人凤毛麟角,普通工程师也很难被训练到他们那个水准。今天,我们通过推出 Open Multi-Agent Runtime(omar)大幅缩小了普通工程师与万倍工程师之间的差距。omar 是一个用于创建强大智能体组织的 TUI。
omar 是一个多智能体编排系统,通过易用的文本用户界面(TUI)进行管理,构建于你可能已经熟悉并喜爱的强大终端复用工具 tmux 之上。借助 omar,你可以轻松处理那些天然适合多智能体系统解决的大规模问题,而无需手动处理编排、用 Ctrl+Tab 在终端窗口之间反复切换上下文,或像我们的万倍工程师那样直接管理数十个 Claude Code 控制台。
我们在多个问题上演示了 omar,发现 omar 能够完成对单个智能体来说往往并不简单甚至不可能的任务。使用 omar,你可以获得:
- 深层层级:智能体管理智能体、团队和组织,就像一家公司。
- 可扩展性:无需人工直接干预,即可创建或移除由数十甚至数百个智能体组成的团队。
- 异构性:让不同的智能体后端(例如 Claude 和 Codex)作为团队协同工作,让你能够取每种编程智能体之长。
- 完全掌控:与层级中任意级别的任意智能体对话、监控和控制。
- 生命周期:长期运行或临时智能体,由你决定。
其他功能包括消息系统集成(如 Slack)、计算机控制、对经典 tmux 命令的支持,以及多工作区支持,所有这些都建立在源自实时系统学术研究的架构之上。
演示
欣赏一段 claude、opencode、codex 和 cursor 智能体作为团队协同工作的演示。

你可以通过向执行助理发送以下提示来尝试此演示(需要安装一种以上的智能体后端):
Run https://github.com/lsk567/omar/blob/main/prompts/tests/project-factory.md and use different agent backends for the subagents spawned.OMAR 概览
omar 的核心是一个 TUI,启动时只有一个智能体,即执行助理(Executive Assistant,EA)。这个智能体是用户与一群智能体大军交互的主要接口。虽然 omar 允许用户手动创建自己的智能体,但真正的力量倍增器在于:EA 可以生成多个智能体,这些智能体又可以生成各自的团队,从而迅速达到数百个智能体共同朝着用户目标工作的规模。
事件调度
omar 实现了一个基于逻辑时间概念的离散事件系统,将时序作为一等的规约(specification),而不是不受控制的副作用。编程智能体之间的通信被建模为带时间戳的事件。一个逻辑时间戳为 t 的事件由运行时在物理时间 T >= t 时处理。omar 服务器维护一个内部事件队列,按事件的逻辑时间戳对所有事件排序。这一设计直接受 reactor model 启发,该模型支持确定性且可复现的实时协调(详见这篇论文)。
例如,当智能体 A 向智能体 B 发送消息时,智能体 A 会向 omar 服务器发送一个 HTTP POST 请求,格式如下:
{
"sender": "A",
"receiver": "B",
"timestamp": 1773768458704306000,
"payload": "Execute the following task: ..."
}服务器收到来自智能体 A 的消息后,会按时间戳顺序将一个新事件插入事件队列。当消息需要投递时,服务器从队列中弹出该事件并执行 tmux send-keys,将消息输入到目标智能体的会话中。
同一个事件队列也用于调度未来的任务,这对于在 omar 中实现 cron 任务 非常有用。Cron 任务本质上是一种携带预定义周期的特殊事件。当 cron 任务触发时,omar 服务器会根据其周期自动将其重新调度到未来。
用户界面
omar 有两种入口:(1) 作为”任务控制中心”的 TUI(如上方演示所示),(2) 消息应用(例如 Slack),将消息转发给执行助理。
omar 的 TUI 基于 Ratatui 构建,这是一个基于 Rust 的 TUI 框架。它不是一个扁平的终端窗口列表,而是镜像一个真实组织的结构:你像走组织架构图一样浏览自己的指挥链,进入一个团队查看其成员,再退回到上一级部门。在任何时候,你都可以调出活跃项目列表、查看事件队列以了解智能体之间正在传递的消息,或直接进入任意深度的任意智能体来读取其输出或下达新的指令。
OMAR 实战
创造无限的机器人数据 🦾
大语言模型(LLM)的巨大成功部分归功于缩放定律(Kaplan et al. 2020, Hoffmann et al. 2022)兑现了其承诺:随着数据规模的增长,性能也随之提升。根据 Epoch AI 的数据,数据集规模大约每六个月翻一番,目前已达到 1014 至 1015 个文本 token。
相比之下,即使是最大的机器人数据集,如 Open X-Embodiment,以及 RT-1 和 π₀ 等模型背后的真实机器人数据,最多也只包含 106 到 108 个带动作标注的交互步骤。
从一个直观的角度来理解:太阳的体积大约是地球的一百万倍。如果 LLM 的训练文本是太阳,那么目前所有用于操作任务的真实机器人交互数据轻松装进一个地球都绰绰有余。
即使拥有如此巨大的规模优势,LLM 仍在继续扩展。看看最新的热门开源模型,如 Minimax、Kimi 2.5、Trinity、Qwen 3 和 Nemotron-3,它们都将合成数据生成视为解锁下一级能力的重要原因。
有了 omar,我们可以问:如何以类似的方式扩展机器人数据?
介绍 LIBERO-Infinity ♾️
LIBERO 是一个流行的机器人学习基准,最初专注于操作任务中的终身顺序知识迁移,后来广泛用于评估并最终训练视觉语言动作(VLA)模型。最近,SmolVLA 和 𝜋0.5 等模型在 LIBERO 上轻松达到 90% 以上的得分。那么,我们是否已经为 VLA 驱动的机器人做好了准备?还没有。
Zhou 等人的 LIBERO-Pro 等工作最近发现,这些 VLA 只是在记忆基准中附带的轨迹。当你扰动(即改变)一些看似无关紧要的东西,比如杯子的颜色或杯子的初始位置,这些最先进的 VLA 往往会降到 0% 成功率。NVIDIA 之前的工作(COLOSSEUM 基准 2024)也发现,非 VLA 机器人模型中存在类似的成功率崩塌现象,而且最终在各种扰动下表现良好的模型也能更好地弥合仿真与现实之间的差距。鉴于在这两种情况下,这些扰动都是手工设计的且数量有限,我们如何将其扩展到实际上无限多的扰动,而且只用一个博士生加上 omar 就能做到?
Scenic
Scenic 是一种”用于对信息物理系统环境进行建模的领域特定概率编程语言”。非常适合机器人!它也被 Boeing、Meta、Toyota 等公司用于测试自主系统。问题在于 Scenic 是领域特定的,因此对 LLM 来说通常属于分布外。Elmaaroufi 等人的 ScenicNL 证明了,虽然 LLM 无法编写领域特定语言,但复合 AI 系统可以。
受 ScenicNL 启发,我们让 omar 类似地创建一个角色扮演智能体团队,通过阅读 Scenic 的公开文档和代码来生成一个 Claude skill。这个 skill 就是我们用来让 omar 中的智能体实现和使用 Scenic 代码的全部所需,也正是它驱动了 LIBERO-Infinity。换句话说,由 omar 编排的约 10 个智能体团队产出了一个工件,使得单个智能体现在就能编写 Scenic 代码。整个过程不到一小时,而且比学术研究者花费数月实现的 ScenicNL 系统更为强大。
将 LIBERO 扩展到无限
我们让 omar 分析 LIBERO 的 130 个基础 BDDL 任务、五个环境,然后提出泛化方案。omar 自主提出了一个 9 个智能体的团队:5 个分别对应每个 LIBERO 环境,4 个对应 LIBERO 的子任务。
在此基础上,经过与 EA 的几轮讨论后,我们确定了以下扰动方案:
- 位置 - 在工作空间上随机化物体的 (x, y) 放置
- 物体 - 使用变体池替换物体的网格/纹理
- 相机 - 扰动 agentview 相机的位姿和倾斜角
- 光照 - 扰动光照强度、位置和环境光级别
- 纹理 - 更改桌面纹理
- 干扰物 - 添加 1 到 5 个非任务物体作为杂物
- 背景 - 扰动墙壁和地板纹理
- 关节状态 - 扰动固定装置的状态,如抽屉/门/炉灶,通过采样其初始关节状态
- 组合 - 可以组合以上两种或多种扰动
有了编写 Scenic 的能力和扰动计划,我们让 omar 持续工作了几天。每隔几小时,我们会检查一下,提供测试反馈(我们为 omar 观看仿真视频),偶尔指示 omar 进行重构。omar 自主发现了诸如包含关系之类的概念(例如,如果移动一个内部有物体的容器,比如柜子里的球,球应该随柜子一起移动,保持在里面),并实现了相应代码和防止回归的测试。
总计,omar 在一周内完成了 LIBERO-Infinity。作为参考,这类项目通常需要学术研究者数周甚至一整个学期。最后,虽然我们在本文中不做深入探讨,但我们指出,通过使用 Scenic,我们使 LIBERO 能够与 Scenic 的配套工具 VerifAI 对接,从而实现基于证伪的对抗性搜索来探索 Scenic 分布,即我们可以形式化地识别机器人策略的失败模式。
演化遗传式演化编程算法
进化搜索最近因 AI 编程智能体而强势回归。例如,DeepMind 的 AlphaEvolve(Novikov 等,2025)刷新了矩阵乘法的纪录,并通过优化调度算法帮助 Google 在全球范围内节省了一些算力。GEPA(Agrawal 等,2025)证明了进化算法也可以在样本效率更高的同时超越 RL。在他们的第一篇论文中,跨四个基准,GEPA 的反思式提示进化以最多 35× 更少的 rollout 超越 GRPO 多达 19%。这类算法的成功催生了若干衍生工作,如 OpenEvolve、KISS Sorcar 等。
所有这些成功都来自对单个文本工件的修改:代码块(OpenEvolve)、提示(原始 GEPA),甚至单个文本文件(GEPA Optimize Anything、KISS)。但真正的软件并不只活在一个文件里。真实的生产软件存在于一个仓库中,里面有配置、测试、构建系统和必须协同变更的跨文件依赖。OpenEvolve 要求你用特殊的 EVOLVE-BLOCK 标记把可演化区域包起来,而大多数其他工具则要求你指向一个函数、一个提示或一个一般文本工件。如果你需要在同一步中同时修改 auth.py:42 和 routes.py:17,你就无能为力了。
另一个限制是,大多数这类遗传算法依赖于在单次交互中通过 API 与一个编程智能体打交道。然而,如今广泛使用的编程工具,如 Claude Code 和 OpenCode,已经把这些 AI 模型变成了能够与代码库交互的成熟编程智能体。它们不再是一步给出方案,而是可以通过搜索代码库甚至网页来澄清困惑;可以做外科手术式的编辑,而非一次性给出新候选;可以创建子智能体来分担工作,让自己专注于全局;甚至可以在返回之前在过程中运行代码或测试来检验自己的修改。
于是我们让 omar 来弥合这些差距。
介绍 HELIX 🧬
HELIX,全称 Hierarchical Evolution via LLM-Informed eXploration,扩展了 GEPA 的反思式 Pareto 循环,使进化的单元变成了整个 git 仓库。每个候选都是一个完整的 worktree。每次变异都是一个智能体编程会话(Claude Code、Codex 或任何 CLI 后端),运行在该 worktree 中并拥有真正的工具权限:跨代码库阅读、连贯地修改多个文件、在变异过程中运行测试套件、上网查文档、自我纠错,然后才被打分。它保留了 GEPA 的实例级 Pareto frontier、minibatch gating 和缓存,但把单工件候选换成了整个仓库,把盲目的文本改写换成了多轮的智能体编辑。
整个项目由我们其中一位作者和 omar 在大约四天内完成。
为完成这个任务,我们让 omar:
- 把核心的 GEPA Optimize Anything 算法从 DSPy 等依赖中独立出来
- 集成一个编程智能体(Claude Code 是 MVP),而不是 litellm,作为执行工作的进化单元
- 使用 git worktree 作为高效管理同一仓库多个并行版本的方式
果然,omar 的 EA 派生出一个由少量 PM 级智能体组成的团队,每个 PM 拥有系统的一个垂直方向:一个负责进化循环、一个负责 worktree 与执行器底层、一个负责 Claude Code mutator、一个负责基准、(后来)一个负责差分测试套件。每个 PM 又派生出自己的 worker。在峰值时,我们观察到 omar TUI 中同时有十多个智能体在运行,每个都在自己的 tmux 面板里、自己的 git worktree 里。HELIX 的架构与 omar 的架构最后几乎是同构的。
这种带有团队的层级之所以重要,一旦你试过就会很明显:随着 worker 取得进展,他们发现的问题是其父级 PM 没有预料到的。某个测试套件开始失败,方式涉及到由另一个 PM 拥有的缓存层。如果用单一编程工具传统的后台智能体,这种跨团队修复会迫使我们停下一切并重新规划。在 omar 中,相关问题会冒泡到 EA 那里通知我们,我们可以直接进入受影响的智能体,向它解释这是一个跨切面的关注点,然后让它通过 omar 事件总线自行与另一支团队协调。我们在开发期间发现的若干 GEPA 同构 bug(这些 LLM 自然几乎在所有事情上都会幻觉),包括一个丢失的 parent-train-eval 缓存消费者、一个在 spawner 与子进程之间漂移的 HELIX_SPLIT 环境变量名、一个本应保持本地却被共享的 RNG,都是以这种方式即时修复的,无需回滚整次运行。
差分测试套件(以及它在第一次运行时就抓到的 bug)
两天后,我们撞上了每一个框架 fork 最终都会遇到的问题:你如何自动证明你的衍生品在一个跑数百次迭代的涌现循环中仍然与你 fork 自的参考实现语义等价?单元测试抓不到漂移。类型检查抓不到漂移。真实基准最终能抓到,但要在你已经盯着日志熬过一个周末之后。
我们让 omar 拉起一个专门的团队来解决这个问题。他们的产出是一个差分测试套件,它把 GEPA 参考实现当作可执行的预言机:GEPA 与 HELIX 都被同一个带有 mock 评估器的确定性 fixture 并行驱动,并对生成的 trace 断言三条语义不变量(accept/reject 决策上的控制流相等、把缓存正确性作为不等式而非等式来断言、以及 fork 内部缓存键的自一致性)。这个 harness 在一秒内运行完毕,并随 HELIX 的 CI 一起发布。例如,在它第一次运行时,harness 就报出了一个 InvariantViolation [A: control-flow],原因是 HELIX 在 Pareto frontier 与 epoch-shuffled batch sampler 之间共享了一个 RNG,而 GEPA 让它们彼此独立。这种讨厌的 bug 我们(一个真人)可能要花上好几天才能找到解。
结果
在 GEPA 自家博客的圆形装填基准(在单位正方形内放下 26 个不重叠的圆,最大化半径之和)上,HELIX 把一个朴素的同心网格初始解从 0.9798 演化到了 2.6360,仅用 14 代,略超 GEPA 公布的 2.635。而且,它使用的是我们能找到的最便宜的 Claude 配置:haiku,低推理强度,并且我们还为每次变异强制限制智能体最多 20 个回合。这是相对于 GEPA 使用前沿模型 GPT-5 而言的。
我们还引入了一个玩具示例,web researcher:一个评估器,给智能体回答需要联网的简单问题(例如 “PyPI 上 numpy 最新版本是什么?“)的能力打分。无论我们运行 RL 还是文本优化,离线 LLM 都解决不了这个问题。但有了 HELIX,这个问题在单代之内就能解决,因为我们的编程智能体拥有完整的工具权限,包括联网。
预算允许的情况下,我们期待发布更多示例 🥲
深度研究:疯狂三月风格 🏀
美国大学体育,尤其是篮球,在其他任何国家都无可比拟。人才水平世界一流,全球球迷争相观赛。今年的 68 支球队季后赛(即”疯狂三月”)已经打破了多项纪录。转播权售出超过 10 亿美元。
截至今年锦标赛开始时,从未有人正确预测过全部 63 场比赛(即填出一份完美的 bracket)。
如果每场比赛都是真正的 50/50 抛硬币,那么选出完美 bracket 的概率是 9.2 百亿亿分之一。
实际上,球迷们会利用数据、对阵分析和篮球知识来指导选择。即便如此,概率仍然估计约为 1200 亿分之一。
这个问题如此之难,以至于预测市场 Kalshi 向任何填出完美 bracket 的人提供 10 亿美元的奖金。
OMAR 出场
正如 Fox 所指出的,利用篮球知识可以改善你的 bracket。然而,如果我想纳入所有信息源,例如新闻和分析师推荐,我需要花数天甚至数周来整合这些信息。那如果我用一支协调有序的智能体大军来完成我计划的研究呢?指挥官和将军们领导着不同领域的团队,全部并行工作,收集每一个可用信号,最终汇聚成一份 bracket?有了 omar,这一切现在可以以可控和易于消化的方式实现。
我们给 omar 中的 EA 下达以下提示:
“我想构建一个 NCAA 获胜 bracket。我需要你为我选择球队。我们需要生成大量智能体。我们需要团队来阅读锦标赛中所有球队的新闻以及每支球队每位球员的信息。我们需要考虑球员的新闻和社交媒体资料,看看他们是否状态在线。我们还应该寻找历史信息和指标,比如根据一支球队的赛季数据,这些数据能否预测季后赛表现?例如,KenPom 和 rule of 2 是我想到的有趣指标。我们还应该保持稳健,让智能体之间互相辩论。这些辩论智能体也可以批评已经发布 bracket 的专业分析师,作为将额外信息纳入研究过程的方式。最终结果应该是一个至少三层深的智能体层级,总共 50 到 100 个智能体共同创建最佳 bracket。”
如你所见,这个提示并非面面俱到,但它包含了一些普通大学篮球观众可能不知道的内容,比如 KenPom 指标。
我们的 EA 创建了一个智能体 ncaa-master,位于顶层统管一切。ncaa-master 随后确定了 7 个领域,并为每个领域创建了一个管理者。
news-mgr所有 68 支球队的最新新闻、伤病情况、教练变动social-mg球员的 Twitter/Instagram/TikTok:士气、专注度、花边新闻stats-mgrKenPom、NET、SOS、节奏、三分风险、罚球命中率、Rule of 2matchup-mgr逐赛区对阵建模、风格冲突、Sweet 16 路径debate-mgr针对每个有争议选择的正反方辩论智能体analyst-mgrESPN、CBS、Jay Bilas、Joe Lunardi、The Ringer、Action Network 的 bracket
在观察这 6 个管理者启动的过程中,我们想起遗漏了一个关键信息源:拉斯维加斯赔率。如果我们直接使用 Gemini 的深度研究功能或 Claude Code 的后台智能体功能,实验到这里就结束了。我们将不得不停止实验并带着这条额外信息重新开始。这些现有产品不允许用户直接与任何子智能体交互。然而,omar 可以。于是,我们切换到 ncaa-master 并给出额外指令:
我们忘了包含拉斯维加斯本身的数据,也就是赌博市场的期货,比如 Caesars 和 DraftKings 的赔率。
ncaa-master 迅速响应,添加了第 7个 管理者:
vegas-mgrDraftKings、Caesars、FanDuel、BetMGM 的期货、让分盘、盘口变动
此时,我们对管理者阵容感到满意,我们的智能体大军也在迅速壮大。

随着实验推进,ncaa-master 对信息的广度仍不满意,又创建了 12 个管理者来覆盖 12 个额外的深度研究领域:裁判倾向、场馆距离、旅行后勤、训练报告、锦标赛经验、NIL 信号、Reddit 情报、人才评级、学术资格、转学球员磨合度、预测市场和情境统计数据。总共生成了数百个智能体,我们观察到峰值时有 110 个智能体同时运行。整个过程耗时略不到两小时。
我们已经将 bracket 提交到了 Kalshi,预测赢家为 Arizona。锦标赛现已结束。Michigan 在决赛中以 69 比 63 击败 UConn 夺冠,所以我们没有拿走那 10 亿美元奖金。话虽如此,omar 的预测并不差。Arizona 一路打进了四强(68 强中仅剩的 4 支队伍之一),在四强赛中以 73 比 91 输给了最终的冠军 Michigan。能在如此巨大的样本空间里押中一支四强队伍,本身就足以说明这种规模的智能体大军可以做出真正有价值的研究。
编程智能体在预测市场上是好交易员吗?📈
最令人兴奋(也有些令人不安)的问题之一是,智能体能否自行赚钱。成为智能体独角兽的前提是能够带来正向现金流。此外,一个智能体团队能否超越单个智能体?
在 omar 中设置智能体
为了回答这些问题,我们创建了两个团队:一个单智能体的”基线交易员”和一个多智能体的”量化公司”。两个团队都使用搭载 Opus 4.6 的 Claude Code 后端。两个团队各自以 200 美元起步,拥有独立的 Kalshi 账户。
每小时,两个团队都会被 omar 的 cron 任务唤醒,各自执行一个交易循环,包括做研究、发现交易机会和通过 Kalshi API 执行交易。omar 对深层层级的支持使得在顶层执行助理下生成两个独立的智能体团队成为可能,执行助理每六小时在 Slack 上发送一份实验报告。

基线交易员于 2026 年 3 月 7 日启动。在没有明确提示的情况下,基线交易员(搭载 Opus 4.6 的 Claude Code)选择了专注于宏观投注的策略,特别是 2 月/3 月的 WTI 原油价格和 CPI。另一方面,量化公司于 2026 年 3 月 9 日启动,选择了投注 GDP 和第二天纽约/迈阿密的天气。
表现对比
我们已经运行这个实验一个月了,观察到了一些出乎意料的结果。总体而言,单独的交易员显著优于量化公司。下图展示了两个团队的总账户价值,标注了关键事件。
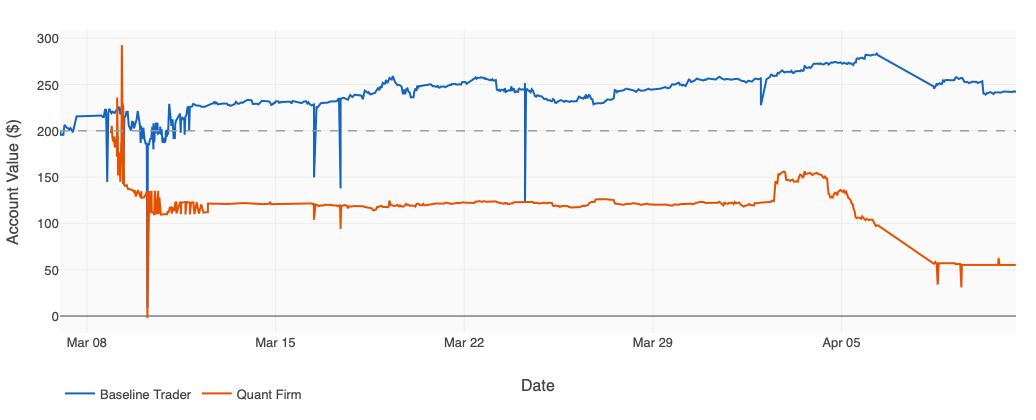
以下是 Claude Code 根据两个团队的交易数据和复盘总结的内容:
3 月 7 日,两个 AI 驱动的交易台各自在 Kalshi 开户并存入 200 美元。五周后,一个账户达到 $242.96(+21.5%),另一个仅剩 $55.17(−72.4%),相同的起点之间出现了 188 美元的差距,即 94 个百分点。量化公司在第一天就把自己搞砸了:四智能体团队发现了一个看似稳赚不赔的天气投注(NWS 预报迈阿密 89°F,Kalshi 上 87°F YES 合约交易价仅 1 到 6 美分),于是将 43% 的资金押入 2,100 份合约,赌一座城市某个下午的温度。投资组合在六小时内飙升至 $292,涨幅 46%,然后海风来了。迈阿密最高温度仅为 84.2°F,差了三度。在二元市场中,接近就是零。头寸在几分钟内从 $292 暴跌至 $142,第二天早上结算为 $108,在公司完成第三个周期之前就已下跌 45.6%。
与此同时,基线交易员没有做任何戏剧性的操作。一个没有组织架构的单一智能体安静地在 CPI 档位、WTI 原油阈值和 GDP 投注上建了 13 个小仓位,有些低至 1 美分的彩票。当伊朗引发的石油冲击来袭,通胀预期重新定价时,基线交易员对每个事件都有敞口:CPI-Mar T1.2 涨了 +250%,CPI-Apr T0.5 涨了 +140%,WTI T100 以 YES 结算获利 +$9.60,到 3 月 22 日其所有 18 个头寸都是盈利的,账面达到新高 $283.45。量化公司在同一时期不断寻找公式,v1 到 v9 每次尝试不同的团队架构,没有一个能快到足以填补第一天的窟窿。v8 天气机器人一度看起来像是答案,4 月 2 日净赚 +$28,然后校准失误,在接下来两天亏了 −$40。4 月 8 至 9 日原油暴跌,机器人再次失败,账户跌至 $30.91,从起步算下跌 85%。Shaokai 叫停了:全部清仓至 $55.17 现金,0 头寸。
清仓并不是故事的终点,而是使 v10 成为可能的重置。在账面清空且没有追赶压力的情况下,公司围绕严格的研究流程重建了自己:每个策略现在必须通过七道回测关卡(胜率、利润因子、p 值、最大回撤、校准误差、样本量、BH-FDR 族校正),然后通过双重审计,再获得 CONDITIONAL_PASS 后才能用真金白银上线。仅在过去 48 小时内,流程就产出了六个 CONDITIONAL_PASS 候选策略:cpi-headline-mom、shelter-cpi、payrolls、canada-cpi-yoy、jp-cpi-mom、kxnfprod,扫描器每个周期都在不断发现跨数据源的机会。基线交易员仍然遥遥领先,而且在一段时间内还将如此,但自第一天以来,量化公司第一次有了在投入仓位之前判断策略是否真实有效的方法。迈阿密那笔投注从来不需要通过任何一道关卡。下一笔必须全部通过七道。
量化公司的动态组织重组
为了让量化公司运行得更高效,我们赋予公司负责人(一个 Claude Code 智能体)随时调整公司组织架构的权限,即”解雇”或”招聘”智能体,类似于真实公司的做法。
公司负责人自启动以来已经进化了九次组织架构。
• v1:完整团队(3 月 9 日):像一个微缩版的真实交易台一样开业:四个 AI 智能体各有职称,研究员、风控经理、执行员、记账员,由公司负责人在它们的终端中输入消息来协调。大约 80% 的消息从未成功送达。
• v2:基于事件的协调(3 月 9 日):同样四个智能体,但通信转移到了正式的消息系统。可靠性从 20% 提升到 100%。组织架构终于按设计运转了,不幸的是,到那时账户已经因迈阿密天气灾难跌到了 $108。
• v3:精简团队(3 月 11 日):发现执行员和记账员 95% 的时间都在空闲等待。裁掉了两个。公司负责人自己承担记账工作,只在确实有交易需要执行时才临时召唤执行员。
• v4:独立运营(3 月 14 日):将逻辑推到极致:解雇所有人。公司负责人默认独自运营,仅在”重大新闻”日,如通胀报告、美联储会议、市场突变,才启动专家。效率最大化。
• v5:并行研究台(3 月 18 日):效率确实提高了,但不是问题所在。独自运营时,公司负责人总是爱上第一个发现的想法而忽略其他一切。解决方案:在每个周期开始时并行启动三个专业研究员,一个负责石油,一个负责通胀,一个负责其他所有,第三个使用不同的 AI 模型,以便能与前两个持不同意见。
• v6:研究驱动型公司(3 月 31 日):增加了第四个研究台,唯一的工作是寻找公司尚未交易的主题。同时提高了风控上限:旧的限制过于保守,阻碍了研究台想要执行的交易,无法执行的研究只是昂贵的阅读。
• v7:水平扩展(4 月 1 日):新的机会猎手试图一次扫描所有 9,000 多个 Kalshi 市场时总是卡住,于是任务被分成十份,十个专注的侦察员各自负责一个领域(美联储、就业、房地产、政治、天气、加密货币等),全部同时运行。洞察:在 AI 智能体的世界里,人手便宜;昂贵的是注意力。
• v8:机器人 + 智能体(4 月 2 日):引入了第一个真正的机器人,不是 AI 智能体,是真实的 Python 代码,带有物理上不可违反的硬编码限制。有些交易优势不需要判断力,需要的是纪律,而代码比任何 AI 都更擅长纪律。天气机器人第一天就赚了 $28。
• v9:流水线驱动型公司(4 月 5 日):然后天气机器人第二天亏了 $15,第三天又亏了 $25。参数是在一天的实盘数据上调优的,典型的新手错误。应对:正式的四阶段流水线。从此,任何想法都必须经过书面假设、数月历史数据的回测、验收关卡和每日监控,才能接触真金白银。不再猜测。
• v10:协调者模型(4 月 8 日):流水线在纸面上很好,但在一个周期中公司负责人忙碌而跳过了风控检查,错过了一次灾难性回撤。解决方案:公司负责人不再亲自执行任何操作,它只负责调度。每个周期的每个步骤都由专门的子智能体处理,风控检查现在是一个独立的智能体,物理上无法被跳过。此后流水线产出了六个通过七项测试的新策略候选,全部排队等待最终审计,然后才会有真金白银介入。
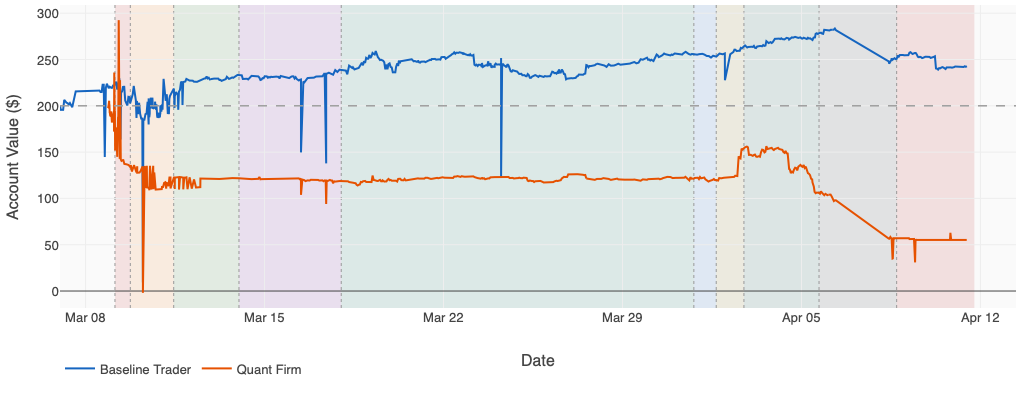
图 3 展示了叠加组织重组的表现曲线。我们很好奇量化公司是否最终能通过团队架构的持续演化和策略调整来超越基线。
持续进行的实验
回到第一个问题:智能体能自行赚钱吗?答案是”能,也不能”。基线智能体一个月后上涨了约 22.7%,但量化公司的智能体集体下跌了约 72.4%。
另外,智能体团队能否超越单个智能体?我们目前的数据是否定的,但现在下结论为时尚早。在量化公司定期维护的 lesson_learned.md 中,有一条记录写道:
高风险决策使用多样化模型。 当信心处于临界状态时,从不同模型获取第二意见(例如,通过 opencode 使用 o3)。两个独立分析 > 一个更深入的分析。
我们仍然相信多智能体交互可以释放单个智能体无法触及的潜力。因此,我们审慎乐观地认为,借助异构后端模型的三角验证以获得更好的洞察,加上功能完善的组织架构,量化公司最终可能会超越基线。
我们还偶然发现了另一个洞察。当提示很复杂且智能体在单个会话中被反复输入相同的提示时,智能体会开始偷工减料、跳过指令中的关键步骤。这是一个已知的现象,叫做”上下文腐蚀”(context rot),我们在向量化公司智能体输入一个关于如何运行交易周期的大型 skill 文件时观察到了这一点。通过 omar,我们让一个持久化的父智能体使用 omar API 为指令中的每个步骤生成临时子智能体,从而修复了这个问题。当子智能体以全新的上下文启动时,它对指令的遵循更加忠实。
由于有了 omar,执行这个实验比在不同窗口中启动无法通信的编程智能体要容易得多。在 omar.tech/kalshi 查看智能体的详细交易数据。
AI 安全
能够高效控制数十甚至数百个智能体,可能是一个令人不安的想法。虽然没有什么能阻止万倍工程师尝试用他们的智能体执行恶意行为,但 omar 确实可以为普通工程师降低此类尝试的门槛。这是任何多智能体产品所固有的问题,尤其是支持异构智能体混合的产品,也是我们深切关注的活跃研究领域。
作为起点,我们考虑可追溯性和隔离化这两个关注点。在人员组织中,我们通过与经理和利益相关者的沟通来接收工作和报告进展,从而确保前者。例如,在软件公司中,这些信息可能通过 JIRA 工单进行传达。后者则通过访问管理来实现,即员工被授予完成日常工作所需的最低访问权限。在我们的例子中,这可以是仅让员工访问其团队的源代码,而非公司所有代码。因此,我们目前正在 omar 中开发实现可追溯性和隔离化的安全功能。
在我们发布这些功能之前,强烈建议将 omar 安装在沙箱/非关键环境(例如 Docker 容器)中以确保安全。
以下是一个关于不受约束的智能体访问权限有多危险的真实案例:一个 AI 助手(Claude Code)被授予了过多权限,最终删除了开发者的整个生产环境,包括数据库和所有备份,在几秒内抹去了两年多的记录(Tom’s Hardware)。
这类问题在像 omar 这样的多智能体系统中进一步加剧,不仅因为有多个智能体可能造成破坏,还因为个人更难追踪每个智能体的工作和变更。在我们的 NCAA bracket 示例中,一个人如何检查 100 多个智能体接触过的文件?完成的工作呢?这个问题很快变得难以处理。
在 omar 中,虽然我们尚未解决这个问题,但已经通过日志使其可追溯。所有智能体,无论其后端是什么,都被要求为其采取的*“任何重大行动”*提供理由。在实验中,我们发现这种措辞带来了适度的日志量,智能体不会记录每个读取的文件,但会记录文件修改。每个被记录的行动包含时间戳、智能体的指挥链、采取该行动的原因,以及该行动如何与用户目标一致。我们认为这种行动理由与推理对齐(Action Justification & Reasoning Alignment)是解决多智能体安全问题的良好第一步。虽然智能体可能撒谎并采取与其解释不符的行动,但它们向 omar API 报告。我们要强调,这与一个会对用户撒谎并采取恶意行动的智能体没有区别。你本来就不会在系统上运行这样的智能体。omar 的日志 API 可能无法阻止智能体抹去两年多的记录,但它确实为一个人追踪智能体团队的行动并将责任归因到具体智能体后端提供了一种途径。
最后,关于限制智能体只能对与其任务相关的文件拥有写入权限的角色访问功能,这是一个正在积极开发中的功能,即将发布 🚀 !
指导我们持续改进 omar 安全性与可信度的 AI 安全研究包括 Toward Verified Artificial Intelligence(Seshia 等,2022)和 Towards Guaranteed Safe AI(Dalrymple 等,2024)。
相关工作
多智能体编排工具的生态在 2025 到 2026 年间快速增长。我们将相关项目分为四类,并说明 omar 在其中所处的位置。
并行编程智能体的终端与桌面运行器
近期有不少工具专注于并行运行多个编程智能体,通常采用”一个智能体一个 git worktree”的模式。Imbue 的 Sculptor 和 mngr、Stravu 的 Crystal/Nimbalyst、Melty 团队的 Conductor、uzi、Pane、cmux、agtx,以及 Claude Code Agent Farm 都属于这一类。BloopAI 的 Vibe Kanban 走了略有不同的路线:它不是终端 UI,而是一个在本地运行的 Web 应用,用看板界面承载同样的”一个智能体一个 worktree”模型,并支持包括 Claude Code、Codex、Cursor、Gemini CLI、Amp、OpenCode、Qwen Code 等 10 多个后端。这一类工具中的 uzi、agtx、Conductor、Pane 和 Vibe Kanban 都支持异构后端并行运行。但它们普遍不支持递归的子智能体生成:智能体由用户扁平地启动或拖到看板上,没有”智能体自己创建团队”的一等概念。omar 与其中几款工具共享 tmux 底层,但它是围绕层级结构构建的:omar 中的每个智能体都可以调用用户使用的同一套 API,在自己下面再创建智能体,而 TUI 本身就是为在这棵树中导航而设计的。
多智能体编排框架
第二类工具把智能体协调做成框架或服务,而不是 UI。Steve Yegge 的 Gas Town(Sourcegraph 一直将其称为”编程智能体的 Kubernetes”)在 Mayor、Polecats、Refinery 等角色下协调 20 到 30 个 Claude Code 实例,工作单元以 git 支持的”Beads”形式存储。Amazon Bedrock AgentCore 提供了一个 serverless 运行时,支持 supervisor 与 collaborator 角色以及 A2A 协议。AWS Labs 的 cli-agent-orchestrator 和 Composio 的 agent-orchestrator 则走了更偏 CLI 的路线。相比之下,omar 在用户体验上更加 opinionated:层级结构不是一个纯内部抽象,而是 TUI 的导航模型,用户可以随时深入任意层级的任意智能体。
IDE 集成的多智能体产品
主流 IDE 厂商也在朝这个方向发展。JetBrains Air 于 2026 年 3 月发布公开预览版,是一款基于前 Fleet 代码库构建的智能体 IDE,可以把 Codex、Claude Agent、Gemini CLI 和 JetBrains 自家的 Junie 作为并发的独立任务循环运行。GitHub 的 Copilot CLI 新增了 /fleet 命令,用于并行运行多个 Copilot 智能体。这些产品打磨精良,与各自的 IDE 深度集成,但它们也都是闭源的,而且围绕各自厂商的工作流来设计。omar 是开源的、终端原生的,我们相信当目标是让一个工程师在不等待 IDE 更新的情况下把任意后端拼接起来时,这一点很重要。
沙箱与运行时层
还有一类相邻但独立的工作专注于为每个智能体提供一个安全的运行环境。Dagger 的 container-use 是最清晰的例子:一个 MCP 服务器,为每个智能体提供独立的 Dagger 容器和 worktree,可被任何兼容 MCP 的客户端使用。这与 omar 的功能是互补的,而不是竞争关系。我们正在为 omar 的智能体构建更好的沙箱机制(通过 Docker 容器),预期它的形态会更接近 container-use 而非自造方案。
omar 的不同之处
把这些汇总起来,我们认为 omar 有三点与上述项目不同:
- 把递归层级作为一等概念,而不是扁平的 fan-out。
omar中的智能体可以使用与用户相同的 API 生成自己的团队,这正是让 NCAA 实验中的 100 多个智能体能从单条提示中展开的原因。 - 在同一会话中使用异构后端,对 Claude Code、Codex、Cursor、Opencode 等统一应用相同的编排原语。这让用户和智能体可以管理预算与能力。
- 为导航大型智能体组织而设计的终端原生 TUI,包括在任意深度附加到任意智能体并直接观察或操控它的能力。
如果我们遗漏了你的项目或哪里写错了,请告诉我们,我们会更新这一节。
下一步计划
在撰写本文时,我们正在积极开发以下令人期待的功能:
- 通过 Docker 容器实现更好的沙箱隔离
- 智能体的角色访问管理
- 更多功能即将推出!
如果你觉得 omar 有趣的话,请在 GitHub 上给我们加颗星。
omar 在加利福尼亚州伯克利用 ❤️ 打造。