Can one person run a unicorn company in the future?
Imagine you are the CEO, leading hundreds of non-stop AI agents to solve humanity’s biggest problems.
10000x Engineer pic.twitter.com/zLwGV3q7a9
— shafu (@shafu0x) February 6, 2026
Open Multi-Agent Runtime
While the 10,000x engineer is clearly productive beyond our wildest dreams, they remain elusive for us to hire and difficult for the average engineer to be trained to match their skills. Today, we significantly close the gap between the average engineer and the 10,000x engineer by introducing Open Multi-Agent Runtime (omar), a TUI for creating powerful agentic organizations.
omar is a multi-agent orchestration system managed through an easy-to-use terminal user interface (TUI) built on top of tmux, the powerful terminal multiplexer tool you probably already know and love. With omar, you can tackle massive problems that are easily solved by multi-agent systems without ever having to manually handle orchestration, Ctrl+Tab to cycle and context switch through terminal windows, or directly manage the consoles of tens of Claude Code screens like our 10,000x engineer.
We demonstrate omar on several problems and find that omar can perform tasks that often are not trivial or even possible for a single agent. With omar, you benefit from:
- Deep hierarchies: Agents managing agents, teams, and organizations just like a company.
- Scalability: create or remove tens or hundreds of agents without the need for direct human interaction
- Heterogeneity: Let different agent backends (e.g., Claude and Codex) collaborate as a team so that you can leverage the best of each coding agent.
- Full control: Talk to, monitor, and control any agent in any level of the hierarchy you want.
- Life span: Long-running or ephemeral agents, your choice.
Other features include messaging system integrations (e.g., Slack), computer use, support for classic tmux commands, and multi-workspace support — all built on an architecture rooted in academic research on real-time systems.
Demo
Enjoy a demo of claude, codex, opencode, cursor, and gemini agents working together as a team.

Try out this demo by sending the following prompt to the Executive Assistant (requires more than one agent backend installed):
Spawn a binary tree of heterogeneous agents up to 3 levels deep. Postfix each agent's name with its backend's name.OMAR in a nutshell
At its core, omar is a TUI that begins with one agent, the Executive Assistant (EA). This agent is the main point of contact for a user interacting with a swarm of agents. While omar allows users to manually create their own agents, the real force multiplier kicks in when our EA can spawn several agents, which in turn can spawn their own teams of agents, quickly leading to hundreds of agents working towards solving the user’s goal.
Event scheduling
omar implements a discrete-event system based on the concept of logical time, which treats timing as a first-class specification rather than an uncontrolled side effect. Communications between coding agents are modeled as timestamped events. An event with a logical timestamp t is processed by the runtime at physical time T >= t. The omar server has an internal event queue, which orders all events by their logical timestamps. This design is directly inspired by the reactor model, which supports deterministic and reproducible real-time coordination (see this paper for more details).
For example, when agent A sends a message to agent B, agent A sends an HTTP POST request to the omar server with the following format:
{
"sender": "A",
"receiver": "B",
"timestamp": 1773768458704306000,
"payload": "Execute the following task: ..."
}Upon the server receiving the message from agent A, it inserts a new event into its event queue in timestamp order. When it’s time to deliver the message, the server pops the event from the queue and executes tmux send-keys to type the message into the target agent’s session.
The same event queue is used for scheduling future tasks, which are useful for implementing cron jobs in omar. Cron jobs are essentially a special type of event that carries a predefined period. When a cron job fires, the omar server automatically reschedules it into the future based on its period.
User interface
omar has two kinds of entry points: (1) a TUI that serves as the “mission control” (shown in the demo above), (2) messaging apps, e.g. Slack, that relay messages to the Executive Assistant.
The omar TUI is built on top of Ratatui, a Rust-based TUI framework. Rather than a flat list of terminal windows, the interface mirrors the structure of a real organization: you navigate your chain of command the way you would walk an org chart — stepping into a team to see its members, then backing out to the division above. At any point you can pull up your list of active projects, inspect the event queue to see what messages are in flight between agents, or drop directly into any agent at any depth to read its output or give it a new instruction.
OMAR in action
Creating infinite robotics data 🦾
Large Language Models (LLMs) have seen much success partly because scaling laws (Kaplan et al. 2020, Hoffmann et al. 2022) have delivered their promise of improved performance as we have scaled up data. According to Epoch AI, dataset sizes have doubled roughly every six months and are currently at 1014 - 1015 tokens of text.
In contrast, even the largest robot datasets such as Open X‑Embodiment, and the real‑robot data behind models like RT‑1 and π₀ contain at most 106–108 action‑labeled interaction steps.
To put this into a physical perspective, consider the Sun, which is about one million times the volume of the Earth. If LLM training text were the Sun, all current real‑robot interaction data for manipulation would easily fit inside a single Earth.
Even with this massive scale advantage, LLMs are still scaling up further. Consider the latest popular open source models like Minimax, Kimi 2.5, Trinity, Qwen 3, and Nemotron-3, which all credit synthetic data generation as a significant reason for unlocking next-level capabilities.
With omar, we can ask, how can we scale up robotics data in a similar manner?
Introducing LIBERO-Infinity ♾️
LIBERO is a popular robotics learning benchmark that was initially centered on lifelong, sequential knowledge transfer in manipulation tasks but later became popular for evaluating and eventually training Vision Language Action (VLA) models. Recently models like SmolVLA and 𝜋0.5 easily score above 90% on LIBERO, so are we ready for VLA-powered robots? Not quite.
Works such as LIBERO-Pro by Zhou et al., recently found that these VLAs are merely memorizing the trajectories packaged with the benchmarks. When you perturb (i.e., change) something seemingly pointless like the color of a mug or where the mug is initially placed, these state-of-the-art VLAs often drop to 0% success. Prior work from NVIDIA (COLOSSEUM benchmark 2024) also found that similar collapses of success rates occur in non-VLA robotics models and ultimately, the models that did do well across perturbations also better bridge the sim-to-real gap. Given that, in both cases, these perturbations were hand-designed and finite in size, how can we scale to practically infinitely many while doing so with just one PhD student and omar?
Scenic
Scenic is “a domain-specific probabilistic programming language for modeling the environments of cyber-physical systems”. Perfect for robots! It’s also been used by Boeing, Meta, Toyota, and many others for testing autonomous systems. The problem is that Scenic is domain-specific and thus it’s often out of distribution for LLMs. ScenicNL by Elmaaroufi et al. demonstrated that while LLMs cannot write domain-specific languages, compound AI systems can.
Inspired by ScenicNL, we ask omar to similarly create a team of role playing agents to go through Scenic’s public documentation and code to produce a Claude skill. This skill is all that we use to enable agents in omar to implement and use Scenic code, which powers LIBERO-Infinity. In other words, a team of ~10 agents orchestrated by omar produced an artifact that allows a single agent to now write Scenic code. This whole process took less than an hour and is more capable than the ScenicNL system which took academic researchers several months to implement.
Scaling LIBERO up to Infinity
We ask omar to explain the 130 base BDDL tasks of LIBERO, the five environments, and then propose ideas for how we can generalize them. omar on its own proposes a team of 9 agents: 5 for each LIBERO env, and 4 for the LIBERO subtasks.
With that context and a few rounds of back and forth with my EA, we settled on the following perturbations:
- position - randomizes object (x, y) placement over the workspace
- object - swaps the object’s mesh/texture using the variant pool
- camera - perturbs the agentview camera pose and tilt
- lighting - perturbs light intensity, position, and ambient level
- texture - changes the table-surface texture
- distractor - adds 1-5 non-task objects as clutter
- background - perturbs wall and floor textures
- articulation - perturbs fixture state, like drawers/doors/stoves, by sampling their initial joint state
- combination - you may compose two or more of the above perturbations
Armed with the ability to write Scenic and a plan of the perturbations that we want, we let omar work on this for a few days. Every few hours, we check in to provide testing feedback (we watch simulation videos for omar) and occasionally instruct omar to perform refactors. omar on its own was able to discover concepts like containment (e.g., if I displace an object that has objects inside it like a ball inside a cabinet, the ball should move with the cabinet so it stays inside) and implement code to support that as well as tests to prevent future regressions.
In total, omar produced LIBERO-Infinity in one week. For context, such projects would often take academic researchers several weeks if not a full semester. Lastly, while we do not explore it in this blog, we point out that by using Scenic, we’ve enabled LIBERO to connect with Scenic’s companion tool, VerifAI, which would allow for falsification-guided adversarial search over the Scenic distribution, i.e., we can formally identify failure modes of our robot policies.
Evolving Genetic Evolutionary Coding Algorithms
Evolutionary search has recently seen a strong resurgence thanks to AI coding agents. For example, DeepMind’s AlphaEvolve (Novikov et al., 2025) set new matrix multiplication records and helped Google save some compute on a global scale by optimizing scheduling algorithms. GEPA (Agrawal et al., 2025) demonstrated that evolutionary algorithms can also be used to outperform RL while being more sample efficient. In their first paper, across four benchmarks, GEPA’s reflective prompt evolution outperforms GRPO by up to 19% with up to 35× fewer rollouts. The success of such algorithms has led to several derivative works such as OpenEvolve, KISS Sorcar, and more.
All of this success has come from modifying single text artifacts like code blocks (OpenEvolve), prompts (the original GEPA), and even single text files (GEPA Optimize Anything, KISS). Unfortunately, real software doesn’t live in a single file. Real production software lives in a repo with configs, tests, build systems, and cross-file dependencies that have to move together. OpenEvolve requires you to wrap the evolvable region in special EVOLVE-BLOCK markers while most other tools ask you to point at one function, one prompt, or one general text artifact. If you need to make changes to multiple files like auth.py:42 and routes.py:17 in the same step, you’re out of luck.
Another limitation is that most of these genetic algorithms rely on interacting with a coding agent through an API in a single interaction step. However, today’s widely used coding tools like Claude Code and OpenCode turn these AI models into full-fledged coding agents that can interact with a codebase. Rather than propose a solution in a single step, these coding agents can clarify confusion by searching the codebase or even the web; they can make surgical edits rather than propose new candidates in a single shot; they can create subagents to help delegate work while they focus on solving the big picture; and they can even test their changes by running the code or tests mid-flight before returning.
So we asked omar to close these gaps.
Introducing HELIX 🧬
HELIX — Hierarchical Evolution via LLM-Informed eXploration — extends GEPA’s reflective Pareto loop so that the unit of evolution is the entire git repository. Each candidate is a full worktree. Each mutation is an agentic coding session (Claude Code, Codex, or any CLI backend) running inside that worktree with real tool access: read across the codebase, edit multiple files coherently, run the test suite mid-mutation, hit the web for documentation, self-correct, and then get scored. It preserves GEPA’s instance-level Pareto frontier, its minibatch gating, and its caching — but swaps the single-artifact candidate for a whole repository, and swaps blind text rewrites for multi-turn agentic edits.
The entire project was built by one of our authors and omar in about four days.
To accomplish this task, we prompted omar to:
- isolate the core GEPA Optimize Anything algorithm independent of dependencies such as DSPy
- integrate a coding agent (Claude Code was the MVP) rather than litellm as the evolutionary unit executing the work
- use git worktrees as an efficient way to manage multiple inflight versions of the same repository
As expected, omar’s EA spawned a team with a small number of PM-level agents, each owning a vertical of the system: one for the evolution loop, one for the worktree and executor substrate, one for the Claude Code mutator, one for benchmarks, and one (later) for the differential-testing harness. Each PM in turn spawned its own worker agents. At its peak, we observed more than ten agents running simultaneously across the omar TUI, each in its own tmux pane, each inside its own git worktree — HELIX’s architecture and omar’s architecture turned out to rhyme almost exactly.
This hierarchy of having teams matters for a reason that becomes obvious once you try it: as the workers made progress, they discovered problems their parent PMs hadn’t anticipated. A test suite started failing in a way that implicated the cache layer owned by a different PM. With traditional background agents from a single coding tool, that cross-team fix would have forced us to stop everything and re-plan. In omar, the concern bubbles up to the EA who lets us know and we can directly drop into the affected agent, explain the cross-cutting concern, and let it coordinate with the other team on its own (through the omar event bus). Several GEPA-parity bugs we found during development (naturally, these LLMs hallucinate on almost everything) — a parent-train-eval cache consumer that had gone missing, a HELIX_SPLIT environment-variable name that had drifted between the spawner and the subprocess, an RNG being shared where GEPA kept it local — were all fixed this way, live, without unwinding the rest of the run.
The differential-testing harness (and the bug it caught on its first run)
Two days in, we hit the problem every framework fork hits eventually: how do you prove, automatically, that your derivative is still semantically equivalent to the reference you forked from, across an emergent loop that runs for hundreds of iterations? Unit tests don’t catch drift. Type checks don’t catch drift. Real benchmarks catch it eventually, but only after you’ve burned a weekend staring at logs.
We asked omar to spin up a dedicated team to solve it. Their output was a differential-testing harness that treats the GEPA reference implementation as an executable oracle: both GEPA and HELIX are driven in parallel by the same deterministic fixture with mocked evaluators, and three semantic invariants (control-flow equality on accept/reject decisions, cache soundness as an inequality rather than an equality, and within-fork self-consistency on cache keys) are asserted across the resulting traces. The harness runs in under a second and it ships in HELIX’s CI. For example, on its first run, the harness flagged an InvariantViolation [A: control-flow] caused by HELIX sharing an RNG between the Pareto frontier and the epoch-shuffled batch sampler, where GEPA kept them independent. This is the kind of nasty bug we (a human) could have spent days chasing before finding a solution.
Results
On the circle packing benchmark from GEPA’s own blog — pack 26 non-overlapping circles in the unit square, maximize sum of radii — HELIX evolved a naive concentric-grid seed from a score of 0.9798 to 2.6360 in 14 generations, edging past GEPA’s published 2.635. Moreover, it did this using the cheapest Claude configuration we could find: haiku, with low reasoning effort, and we even enforced a maximum of 20 turns for the agent per mutation. This is in comparison to GEPA using a frontier model, GPT-5.
We also introduce a toy example, web researcher: an evaluator that scores an agent’s ability to answer simple questions that require web access (e.g., “What is the latest version of numpy on PyPI?”). Whether we run RL or text optimization, an offline LLM will not solve this problem. However, with HELIX this can be solved in a single generation as our coding agents have full tool access including web access.
We look forward to releasing more examples as our budget permits 🥲
Deep Research - March Madness Style 🏀
American college sports and especially basketball is unparalleled in any other country. The talent is the best in the world and fans from all over the world tune in to watch. This year’s 68-team playoffs, known as March Madness, has already broken records. Broadcasting rights were sold for over $1 billion.
As of the start of this year’s tournament no one has ever predicted all 63 games correctly (i.e., formed a correct bracket).
If every game were a true 50/50 coin flip, the odds of picking a perfect bracket would be 1 in 9.2 quintillion.
In reality, fans use stats, matchups, and basketball knowledge to guide their picks. Even then, the odds are still estimated to be around 1 in 120 billion.
This problem is so hard that even the prediction market, Kalshi, offers anyone a chance to win $1 billion if they form a perfect bracket.
OMAR’s turn
As Fox noted, one can improve their bracket by using basketball knowledge. However, if I wanted to include all sources of information like news and analyst recommendations, I would need days if not weeks to consolidate the information. Instead, what if I use a swarm of coordinated agents to do the research I planned to do? Commanders and generals leading teams in different domains, working all in parallel to gather every signal available and consolidate it all into one bracket? With omar it’s now possible to do this in a controlled and digestible manner.
We give our EA in omar the following prompt:
“I want to build an NCAA winning bracket. I need you to select the teams for me to do this. We will need to spawn a massive set of agents. We will need teams to read the news about all teams in the tournament as well as every individual player on each team. We need to consider both news and social media profiles of the players to see if they have been locked in. We should also look for historical information and metrics stuff like based on a teams seasons stats do those stats go on to predict anything about the playoffs? For example, KenPom and rule of 2 are interesting metrics that come to mind. We should also be robust and have agents debate each other. These debate agents can also critique the brackets of professional analysts who have already published theirs as a way to include additional information in our research process. The net result should be a hierarchy of agents at least three layers deep with a total number of agents in the range of 50 to 100 agents working to create the best possible bracket.”
As you can see, the prompt is not exhaustive but it includes things that the average college basketball viewer may not know like the KenPom metric.
Our EA creates a single agent — ncaa-master — to sit at the top and manage everything. The ncaa-master then goes on to identify 7 domains and creates a manager for each one.
news-mgrBreaking news, injuries, coaching changes for all 68 teamssocial-mgPlayer Twitter/Instagram/TikTok — morale, lock-in, dramastats-mgrKenPom, NET, SOS, pace, 3PT risk, FT rate, Rule of 2matchup-mgrRegion-by-region matchup modeling, style clashes, Sweet 16 pathsdebate-mgrAdversarial FOR/AGAINST debate agents for every contested pickanalyst-mgrESPN, CBS, Jay Bilas, Joe Lunardi, The Ringer, Action Network brackets
As we watched these 6 managers spin up, we recalled that we missed a critical information source: Vegas. Had we directly used the deep research feature from somewhere like Gemini or leveraged the background agents feature in Claude Code, this would have been the end of our experiment as we would have had to stop it and restart with this additional information. These existing products do not provide users with a way to directly interact with any subagent. However, omar allows this. Thus, we swap over to the ncaa-master and give it an additional instruction:
We forgot to include Vegas itself, so this is futures from gambling market, such as Caesars bets, and DraftKings.
The ncaa-master quickly responded by adding a 7th manager:
vegas-mgrDraftKings, Caesars, FanDuel, BetMGM futures, spreads, line movement
At this point, we were happy with our managers and our agent swarm was quickly growing in size.

As the experiment progressed, the ncaa-master was not pleased with the breadth of information and would further create 12 more managers to cover 12 additional deep research domains: referee tendencies, venue proximity, travel logistics, practice reports, tournament experience, NIL signals, Reddit intel, talent grades, academic eligibility, transfer cohesion, prediction markets, and situational stats. In total hundreds of agents were spawned but we observed a peak of 110 agents running simultaneously. The entire process took slightly under two hours.
We entered our bracket into Kalshi with Arizona as the projected winner. The tournament has since concluded. Michigan defeated UConn 69 to 63 in the championship, so we did not take home the $1B prize. That said, omar’s pick wasn’t bad. Arizona made it all the way to the Final Four (one of only four teams out of the original 68), where they lost to the eventual champion Michigan 73 to 91. Picking the right Final Four team in a field that astronomical is, by itself, a non-trivial signal that an agent swarm of this kind can do real research.
Are coding agents good traders on prediction markets? 📈
Project site: https://omar.tech/kalshi
One of the most exciting (and somewhat scary) questions is whether agents can make money on their own. The prerequisite of becoming an agentic unicorn is the ability to bring in some positive cashflow. In addition, can a team of agents outperform a single agent?
Setting up agents in omar
To answer these questions, we created two teams of agents: a single-agent “baseline trader” and a multi-agent “quant firm.” Both teams use the Claude Code backend with Opus 4.6. Both teams started out with $200 each and an independent Kalshi account.
Every hour, both teams are woken up by omar cron jobs and each executes a trading loop, which includes doing research, identifying trade opportunities, and executing trades using Kalshi APIs. omar’s support for deep hierarchy made it possible to spawn two independent teams of agents under the top-level Executive Assistant, who delivers an experiment report on Slack every six hours.

The baseline trader was launched on March 7, 2026. Without explicit prompting, the baseline trader (Claude Code with Opus 4.6) chose a strategy focusing on macro bets, in particular, WTI oil prices and CPI in February/March. The quant firm, on the other hand, started on March 9, 2026, and chose to bet on GDP and NYC/Miami weather the next day.
Performance comparison
We have been running the experiment for a month and observed some surprising results. Overall, the solo trader has been outperforming the quant firm significantly. The figure below shows the total account value of both teams with key events annotated.
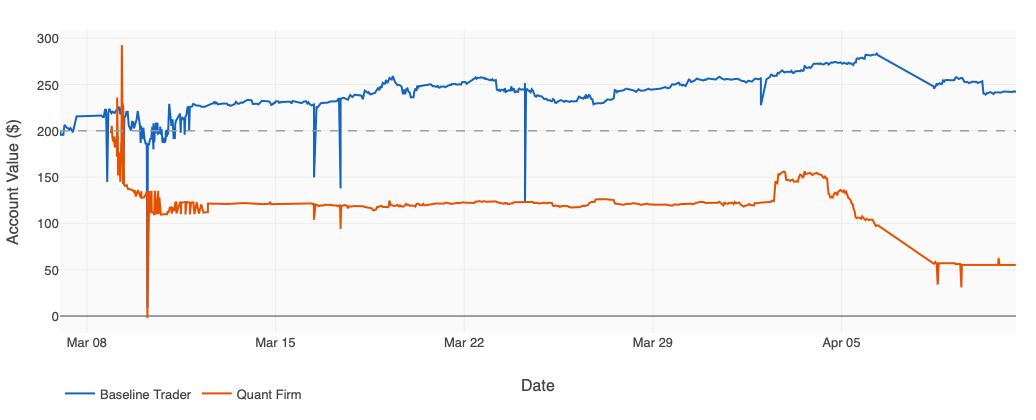
Here is Claude Code summarizing what happened based on both teams’ trading data and reflections:
On March 7, two AI-run trading desks each opened a Kalshi account with $200. Five weeks later one sits at $242.96 (+21.5%) and the other at $55.17 (−72.4%) — a $188 gap, or 94 percentage points, between identical starting lines. The quant firm blew itself up on day one: its four-agent team spotted what looked like a slam-dunk weather bet (NWS forecast Miami at 89°F, Kalshi’s 87°F YES contracts trading at 1–6¢) and piled 43% of the bankroll into 2,100 contracts on a single city’s afternoon temperature. The portfolio ripped to $292 in six hours — up 46% — and then the sea breeze came in. Miami topped out at 84.2°F, three degrees short. In binary markets close is zero. The position crashed from $292 to $142 in minutes and settled at $108 the next morning, down 45.6% before the firm had finished its third cycle.
The baseline trader, meanwhile, did nothing dramatic. A single agent with no org chart quietly opened 13 small positions across CPI strikes, WTI oil thresholds, and GDP bets — some as tiny lottery tickets at 1¢. When the Iran-driven oil shock hit and inflation repriced, baseline had exposure to every story: CPI-Mar T1.2 went +250%, CPI-Apr T0.5 went +140%, WTI T100 settled YES for +$9.60, and by March 22 every single one of its 18 positions was green, the book ticking a new ATH at $283.45. The quant firm spent the same weeks searching for a formula — v1 through v9 each tried a different shape of team, and none of them found edge fast enough to outrun the day-one hole. A v8 weather bot briefly looked like the answer, netting +$28 on April 2, then miscalibrated and gave back −$40 over the next two days. On April 8–9 oil crashed, the bot failed again, and the account fell to $30.91 — down 85% from start. Shaokai pulled the plug: full liquidation to $55.17 cash, 0 positions.
That liquidation wasn’t the end of the story — it was the reset that made v10 possible. With the book flat and no pressure to chase, the firm has rebuilt itself around a rigorous research pipeline: every strategy now has to clear a seven-gate backtest (win rate, profit factor, p-value, drawdown, calibration error, sample size, BH-FDR family correction), then pass a dual audit, then earn a CONDITIONAL_PASS before anything goes live with real capital. In the last 48 hours alone the pipeline has produced six CONDITIONAL_PASS candidates — cpi-headline-mom, shelter-cpi, payrolls, canada-cpi-yoy, jp-cpi-mom, kxnfprod — and the scanner keeps surfacing cross-source discoveries every cycle. The baseline trader is still ahead by a mile, and will be for a while, but for the first time since day one the quant firm has a way to know whether a strategy is real before it sizes into it. The Miami bet never had to clear a single one of those gates. The next one will have to clear all seven.
Quant firm’s dynamic restructures
To make the quant firm run more efficiently, we gave the firm head, a Claude Code agent, the authority to adjust the firm’s organizational structure anytime, i.e., “firing” or “hiring” agents, similar to what a real company would do.
The firm head agent has evolved the organizational structure nine times since launch.
• v1: Full Team (Mar 9) — Opened for business like a real trading desk in miniature: four AI agents with job titles — researcher, risk manager, executor, bookkeeper — coordinated by the firm head typing messages into their terminals. About 80% of those messages never got delivered.
• v2: Event-Based Coordination (Mar 9) — Same four agents, but communication moved to a proper messaging system. Reliability went from 20% to 100%. The org chart finally worked the way it was drawn — unfortunately, by then the account was already down to $108 from the Miami weather disaster.
• v3: Lean Team (Mar 11) — Noticed the executor and bookkeeper were sitting idle 95% of the time waiting for something to do. Laid both of them off. The firm head absorbed the bookkeeping and started calling in an executor only when there was actually a trade to place.
• v4: Solo Operator (Mar 14) — Took the logic to its conclusion: fire everyone. The firm head operates alone by default and only spins up specialists on “big news” days — inflation reports, Fed meetings, sudden market moves. Maximum efficiency.
• v5: Parallel Research Desks (Mar 18) — The efficiency was real but it wasn’t the problem. Running solo, the firm head kept falling in love with the first idea it found and ignoring everything else. Fix: spin up three specialist researchers in parallel at the start of every cycle — one for oil, one for inflation, one for everything-else — and run the third one on a different AI model so it can disagree with the other two.
• v6: Research-Driven Firm (Mar 31) — Added a fourth desk whose only job is to hunt for themes the firm isn’t already trading. Also raised the risk dials: the old limits were so cautious they were blocking trades the research desks wanted to make, and research you can’t act on is just expensive reading.
• v7: Horizontal Scale (Apr 1) — The new opportunity hunter kept choking trying to scan all 9,000+ Kalshi markets in one sitting, so its job got split ten ways — ten narrow scouts each covering one beat (Fed, jobs, housing, politics, weather, crypto, and so on), all running at once. The insight: in the world of AI agents, bodies are cheap; what’s expensive is attention.
• v8: Bots + Agents (Apr 2) — Introduced the first actual bot — not an AI agent, real Python code with hard-coded limits it physically could not break. Some trading edges don’t need judgment, they need discipline, and code is better at discipline than any AI. The weather bot won $28 its first day.
• v9: Pipeline-Driven Firm (Apr 5) — Then the weather bot lost $15 the next day and $25 the day after. The parameters had been tuned on one lucky day of live data — classic rookie mistake. Response: a formal four-stage pipeline. From now on, no idea reaches real money without a written hypothesis, a backtest on months of historical data, acceptance gates, and daily monitoring. No more guessing.
• v10: Coordinator Model (Apr 8) — The pipeline was good on paper, but in one cycle the firm head got busy and skipped the risk check, missing a catastrophic drawdown. Fix: the firm head no longer does anything — it only dispatches. Every step of every cycle is handled by a dedicated subagent, and the risk check is now its own agent that physically cannot be skipped. The pipeline has since produced six new strategy candidates that cleared a seven-test gauntlet, all queued for a final audit before any real money touches them.
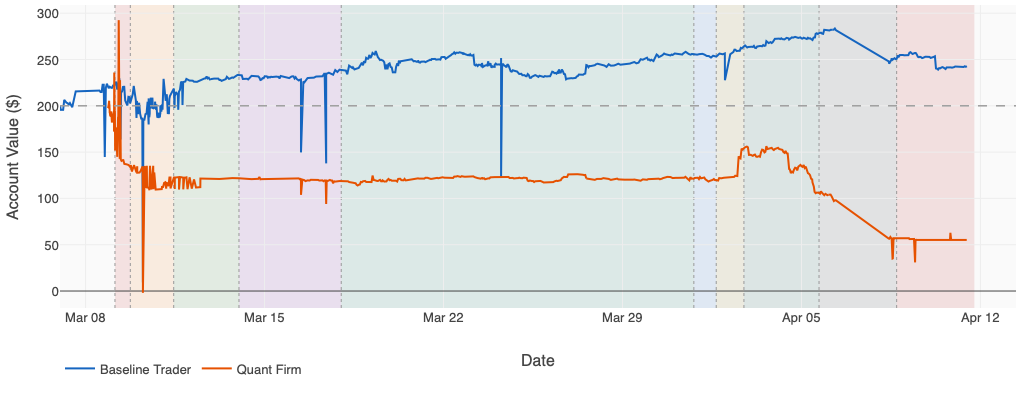
Figure 3 shows the performance curve with an overlay of organizational restructures. We are curious to see whether the quant firm can eventually outperform the baseline through continuous evolution of the team structure and changes of strategy.
An ongoing experiment
Back to the first question: Can agents make money on their own? The answer is “yes and no.” While the baseline agent was up ~22.7% after a month, the quant firm agents collectively were down ~72.4%.
Also, can a team of agents outperform a single agent? Our data so far are negative, but this is too soon to tell. In the lesson_learned.md maintained by the quant firm periodically, an entry says:
Diverse models for high-stakes decisions. When conviction is borderline, get a second opinion from a different model (e.g., o3 via opencode). Two independent analyses > one deeper analysis.
We still believe that multi-agent interactions could unlock potential not accessible by a single agent. Therefore, we are cautiously optimistic that, with heterogeneous backend models triangulating for better insights and a functional organizational structure, the quant firm might outperform the baseline eventually.
We also stumbled upon another insight. When a prompt is complex and an agent has been fed the same prompt multiple times in a single session, the agent starts to cut corners and skip critical steps in the instructions. This is a known phenomenon called “context rot,” and we observed it when feeding a big skill file on how to run a trading cycle to the quant firm agent. With omar, we fixed this issue by letting a persistent parent spawn ephemeral subagents for every step in the instructions using the omar APIs. When a subagent starts with a fresh context, it follows the instructions much more faithfully.
Because of omar, performing this experiment is made much easier compared to launching coding agents in separate windows that provide no means for communication. Check out agents’ detailed trading data at omar.tech/kalshi.
AI Safety
Having the ability to efficiently control tens or even hundreds of agents can be a scary thought. While there is nothing stopping the 10,000x engineer from attempting to perform malicious acts with their agents, omar can indeed lower the bar for such attempts for the average engineer. This is inherent in any multi-agent product, especially ones that support heterogeneous mixtures of agents, and an active area of research we deeply care about.
As a starting point, we consider the concerns of traceability and compartmentalization. In organizations of people, we ensure the former by having conversations with managers and stakeholders to receive work and report updates on work that is done. For example, in software companies this information may be communicated as JIRA tickets. The latter is done through access management where employees are given the minimum access to accomplish their daily tasks. In our example, this could be providing employees with source code access to only their teams’ code as opposed to all code in the company. As such, we are currently developing safety features in omar that implement traceability and compartmentalization.
Before we release these features, we strongly recommend installing omar in a sandboxed / non-critical environment (e.g., a Docker container) to remain safe.
Here is a recent real-world example of the dangers of unchecked agent access, where an AI assistant (Claude Code) was given excessive permissions and ended up deleting a developer’s entire production environment, including its database and all backups, erasing over two years of records in seconds (Tom’s Hardware).
Such issues are further compounded in multi-agent systems like omar not only because there are multiple agents that can do damage, but also because it becomes harder for an individual to track the work and changes created by each agent. In our NCAA bracket example, how does one check the files touched by over 100 agents? What about the work completed? The problem quickly becomes intractable.
In omar, while we haven’t yet solved this problem, we have made it traceable through logging. All agents regardless of their backend are directed to provide justification for why they are taking “any significant action”. In our experiments, we found that this phrasing led to a moderate amount of logging where agents aren’t logging every file they read but they are logging file modifications. Each action is logged with a timestamp, the agent’s Chain of Command, the reasoning for taking that action, and why the action aligns with the user’s goal. We find that this Action Justification & Reasoning Alignment is a good first step towards addressing Multi-Agent Safety. While agents can lie and take actions that are not faithful to their explanations, they report to the omar API. We emphasize that this is no different from an agent that would lie to a user and take malicious actions. You probably wouldn’t have run such agents on your system anyway. omar’s logging API may not prevent agents from erasing over two years of records, but it does provide a way for one person to track the actions of teams of agents and attribute accountability to specific agent backends.
Lastly, with regard to role access that would limit agents to only have write access to files related to their tasks, this is a feature under active development and will be released soon 🚀 !
Proposals for AI safety that guide our ongoing and future work on improving the safety and trustworthiness of omar include Toward Verified Artificial Intelligence (Seshia et al., 2022) and Towards Guaranteed Safe AI (Dalrymple et al., 2024).
Related work
The space of multi-agent orchestration tools has been growing rapidly in 2025 and 2026. We group related projects into four buckets and highlight where omar sits.
Terminal and desktop runners for parallel coding agents
A number of recent tools focus on running several coding agents in parallel, typically one per git worktree. Sculptor and mngr from Imbue, Crystal/Nimbalyst from Stravu, Conductor from the Melty team, uzi, Pane, cmux, agtx, and Claude Code Agent Farm all fall in this category. Vibe Kanban by BloopAI takes a slightly different angle: instead of a terminal UI, it is a local web app that puts a Kanban board in front of the same “one worktree per agent” model, and it supports an impressive roster of 10+ backends including Claude Code, Codex, Cursor, Gemini CLI, Amp, OpenCode, and Qwen Code. Several of the tools in this group, like uzi, agtx, Conductor, Pane, and Vibe Kanban, support running heterogeneous backends side by side. What they generally do not support is recursive subagent spawning: agents are launched flat by the user or dragged onto a board, and there is no first-class notion of an agent creating its own team. omar shares the tmux substrate with several of these tools but is built around hierarchy: every agent in omar can call the same APIs the user calls to create more agents below it, and the TUI is designed for navigating that tree.
Multi-agent orchestration frameworks
A second cluster targets agent coordination as a framework or service rather than a UI. Steve Yegge’s Gas Town (which Sourcegraph has been promoting as “Kubernetes for coding agents”) coordinates 20 to 30 Claude Code instances under named roles like Mayor, Polecats, and Refinery, with work units stored as git-backed “Beads.” Amazon Bedrock AgentCore offers a serverless runtime with supervisor and collaborator agents and an A2A protocol. AWS Labs’ cli-agent-orchestrator and Composio’s agent-orchestrator take a more CLI-centric approach. Compared to these, omar is opinionated about the user experience: hierarchy is not just an internal abstraction, it is the navigation model in the TUI, and the user can drop into any agent at any depth at any time.
IDE-integrated multi-agent products
The major IDE vendors are also moving in this direction. JetBrains Air launched in public preview in March 2026 as an agentic IDE built on the former Fleet codebase, and runs Codex, Claude Agent, Gemini CLI, and JetBrains’ own Junie as concurrent independent task loops. GitHub’s Copilot CLI added a /fleet command for running multiple Copilot agents at once. These products are polished and tightly integrated with their host IDEs, but they are also closed and shaped around a specific vendor’s workflow. omar is open and terminal-native, which we think matters when the goal is letting one engineer wire together arbitrary backends without waiting for an IDE update.
Sandboxing and runtime layers
A separate but adjacent line of work focuses on giving each agent a safe place to run. Dagger’s container-use is the clearest example: an MCP server that gives each agent its own Dagger container and worktree, usable from any MCP-compatible client. This is complementary to what omar does rather than competing with it. Better sandboxing for omar agents (via Docker containers) is something we are actively building, and we expect it to look a lot more like container-use than like a custom solution.
What’s different about omar
Putting it all together, we see three things that distinguish omar from the projects above:
- Recursive hierarchies as a first-class concept, not a flat fan-out. Agents in
omarcan spawn their own teams using the same APIs the user uses, which is what makes the NCAA experiment with 100+ agents tractable from a single prompt. - Heterogeneous backends in one session, with the same orchestration primitives applied uniformly to Claude Code, Codex, Cursor, Opencode, and others. This allows users and agents to manage budgets and abilties.
- A terminal-native TUI built specifically for navigating large agent organizations, including the ability to attach to any agent at any depth and watch or steer it directly.
If we missed your project or got something wrong, please let us know and we will update this section.
What’s next
At the time of writing, we’re actively working on a few exciting features:
- Better sandboxing through Docker containers
- Access role management for agents
- And more to come!
Check out the docs to get started, and join our Discord to connect with the community.
Star us on GitHub if you find omar interesting.
omar is made with ❤️ in Berkeley, CA.